|
SECTION ONE
PART I -
BACKGROUND
Chapter 1
A TURNING POINT
Humanity is at a turning point in its history. Down through the ages,
sages in every civilization have said that there is more to life
than merely the flesh and bones within which we dwell. We have
souls, and physical death is but a blink in our awareness. This
concept is easy enough to entertain. From religious beliefs to
reports of life after death, all of us have felt, at one time or
another, that there is something beyond our mortal selves.
The continuum of life, though, may be vaster than we ever realized.
For some time many scientists have believed that we are not alone in
the universe. Scattered throughout the far reaches of space, other
life forms exist. Until recently we have been unable to contact
these beings. Yet if we had a method that combined the intuitive
perception of the sages with the rigor of modern science, then
humans could find their true place in the cosmos.
What needs to be examined is a component of the current "scientific"
worldview that maintains that only that which is physical is real.
The basis of this relatively new religion of scientific atheism is
the belief that consciousness is limited to the physical mind, and
that when the brain stops functioning, consciousness ceases to
exist. When this happens, the personality of the individual is gone
forever. But what if the sages from the past are right? The demise
of scientific atheism would cause people
everywhere to turn inward, in order to seek that which resides
beyond. A new scientific age not divorced from the spiritual would
dawn.
To accomplish this, a new method, a new tool for exploration, is
needed. Based on the explorations of myself and others, I believe
such a method exists. This new and surprisingly accurate method of
data collection is called "remote viewing." There is now a new
scientific field of consciousness that specializes in the study of
this phenomenon. People can be trained to use remote viewing to
collect information across time and space.
Remote viewing is not
easy to do, and to use it with consistent accuracy requires
extensive training and practice. Explicit procedures have been
designed to aid communication between the physical mind and what
many call the "subspace" mind (the soul). Souls exist in subspace,
that vast domain diversely referred to by mystics and theologians
as the etheric realm, heaven, or the afterlife. Humans can learn to
become directly aware of their subspace aspects, normally hidden
from them until they die and their bodies drop away.
Remote viewing has its origins in the procedures developed largely
by
Ingo Swann, working under contract at SRI International (formerly
Stanford Research Institute) in a program that was funded by various
United States governmental agencies, notably the Defense
Intelligence Agency (DIA). This program began in the early 1970s
and continued until 1989. In 1990 the government transferred its
financial support to a program housed at Science Applications
International Corporation (SAIC).
The original primary researchers were
Russell Targ and
Harold Puthoff. Their work in the program involved contact with a number of
scientific luminaries, including
Charles Tart.
Edwin May worked in
the program since the mid 1970s, and he became the project director
in 1986. When subsequent government funding for remote-viewing
research switched to SAIC, Dr. May continued as director.
The current understanding of remote viewing is based on a rich
history of experimentation and discovery. In these two decades the
literature on remote viewing—both historical and otherwise—has grown
to be quite extensive. Over the past few years a number of
scientists and remote viewers have risked public ridicule and their professional reputations to pursue
re-search in this new and controversial field.
While this is not the appropriate setting to present a complete
history of remote viewing, some recently published books contain
detailed historical background of both the scientific and military
investigations into
psi phenomena generally and remote viewing in
particular.
Readers who are interested in this background should
read,
I also strongly recommend interested readers to examine the
Spring 1996 volume of the Journal of Scientific Exploration (Volume
10, number 1), dedicated almost entirely to the scientific history
of remote viewing.
For all its intelligence uses, though, it is remote viewing's
ability to penetrate the subspace realm that has led to knowledge of
an entirely different sort. Most human efforts to contact other
worlds have focused on radio signals or other "hard science" data.
Yet what we have been assuming is that extraterrestrials are limited
to our own fairly unimpressive modes of communication. What has
been discovered through repeated sessions of remote viewing is that
the pathway to other worlds lies in the subspace realm.
Remote-viewing evidence suggests that many extraterrestrial species
are highly telepathic. Indeed, the human species may be unique in
that we have such difficulty perceiving things with our souls while
we are physical beings. We already know the universe is a very
complex place. In this light, demanding that other life forms
communicate only the way we do is tantamount to demanding that the
wind blow the way we say.
By using the tools of consciousness, we may be able to fulfill our
potential and contact more advanced forms of life. By developing
knowledge on the subspace level (that is, the level of the soul), we
could protect ourselves by making educated choices regarding our
own destiny.
Humanity needs vision of all sorts to prosper in a
complex universe, and that total vision includes the ability to
perceive beyond the physical/subspace divide. In a complex universe,
global awareness could not only open new avenues of knowledge, but
protect us from harm. If we had the
ability to interact with other beings, our human energies could
propel us into a future in which we determine our own destiny.
These are uncertain times. As is characteristic of all history,
events will happen in our future that will be unexpected. We need to
add a degree of control to our future evolution. Control is not
obtained through continued ignorance but by increased awareness.
Remote viewing is one way we can increase our knowledge of the
universe.
THE PLAN OF THIS BOOK
Part I is an overview of the mechanics of Scientific Remote Viewing.
It provides the basis for understanding the chapters that follow.
Some readers who read my earlier book,
Cosmic
Voyage, will find the
section involving types of remote-viewing data familiar. But there
are many other elements that have never been published before.
Explaining the mechanics helps remove the mystery from the actual
sessions that are the heart of this book.
Part II contains a series of remote-viewing sessions using
verifiable targets. These chapters are included so that readers can
see how the mechanics of Scientific Remote Viewing work with targets
about which solid data is known. The targets cover a wide range of
substantive areas, and even if the discussion of the
extraterrestrials that follows challenges the belief system of some
readers, the verifiable targets will give everyone something to
think about.
Section 2 of this book contains four parts in which I present new
remote-viewing data involving extraterrestrials currently
interacting with Earth in varying degrees. The chapters in Section
2 contain information that is crucial for everyone who has an open
mind regarding these matters to understand. It contains much of the
substantive basis upon which we, as humans, must decide the course
of our collective future.
This book is not designed to make people feel comfortable. It is
crisis, not confirmation, that assists our species as we make
important evolutionary advances. This book is structured to force
people to confront ideas that do not conform with pre-existing
paradigms.
The truth regarding these issues will not come easily. But the
future potential of humankind rests with our success in creating
this shift in our collective thought. With a little prodding,
humanity may eventually understand and accept these spiritual and
scientific ideas, but we do not have the luxury of waiting. As I
explain in the pages that follow, our options for the future may
soon be dramatically restructured for the worse. Through our own
actions we will define and create our destiny.
Back to Contents
Chapter 2
SCIENTIFIC REMOTE VIEWING
The method of remote viewing that is the
focus of this book began to
evolve in earnest in 1996 due to research that was and continues to
be conducted at
The Farsight Institute. This is a non-profit
research and educational institute based in Atlanta, Georgia, that
is dedicated to the continued development of the science of
consciousness using remote viewing as the primary research tool. I
am the director of the institute.
Underpinning all of the research is the hypothesis that all humans
are composite beings. This means that we have two fundamental
aspects: a soul and a body. In the current jargon of remote viewing,
the soul is called the "subspace aspect" of a person. The physical
realm of solid matter is both separate from and connected to
subspace. Once our physical bodies expire, we are no longer
composite beings, and we continue our existence as subspace
entities.
While we are composite beings, physical stimuli tend to dominate
our awareness. This means that our five senses (taste, touch, sight,
hearing, smell) overshadow the more intuitive awareness originating
from the subspace side. In practical terms, this means that most
people are not aware that they even have a subspace
aspect. In short, soul voices are deafened by the din of our five
physical senses.
In order to break through this noise, specialized techniques are
required. In general, these techniques focus on shifting a per-son's
awareness away from the five physical senses. It is not necessary
to force a shift in one's awareness toward the subspace aspect. This
happens automatically once a person's awareness is no longer riveted
on the physical side of life.
For this reason, I advise combining the practice of remote viewing
with the practice of meditation.
The form of meditation that I enjoy is
Transcendental Meditation (TM), or the more advanced TM-Sidhi
Program. My preference is based on the fact that TM is a mechanical
procedure, and it has no belief or religious requirement associated
with it. The mechanics of TM are also quite stress free and
relaxing. Again, these are only my preferences. Many people who
participate in other programs for the development of consciousness
have also learned remote viewing.
Remote viewing is a natural process of a deeply settled mind. Remote
perception works best when it is not forced in any way I have often
said that the ancient seers were our first human astronauts. While
in a deeply relaxed state, they let their minds roam across the
fabric of the universe, and some perceived what was there with
surprising accuracy.
The subspace mind, the intelligence of the soul, perceives and
processes information differently from the physical mind. All
evidence suggests that the subspace mind is omnipresent across space
and time. It is everywhere at once. Using the capabilities of the
subspace mind, remote viewing involves no more than shifting one's
awareness from one place and time to another. You do not go anywhere
when you remote view. You do not leave your physical body You do not
induce an altered state of consciousness. You merely follow a set
of procedures that allows you to shift your awareness from one area
of your intelligence to another.
As physical beings, though, we must translate the information
perceived by our subspace aspects into physical words, pictures,
and symbols so that this information can be conveyed to others
within the physical realm. Scientific Remote Viewing (SRV)
facilitates this translation. Remote viewing would be impossible
in the absence of the human soul, since it is otherwise physically
impossible for an individual's conscious mind to perceive things
without direct physical contact of some sort.
COMMUNICATING WITH THE SOUL
Soul-level communication is not as easy as you might initially
think. On one level, communication using the soul is as natural as
breathing. While the theoretical principles underlying how this is
done are quite simple, knowing with some degree of certainty that
the communication is accurate is more difficult.
Subspace information has a mental flavor that is distinctly
different from that obtained from the five physical senses. It is
much more subtle and delicate. For this reason, sensory input from
the five physical senses needs to be kept to a minimum both
immediately prior to and during a remote-viewing session. That's why
one begins with meditation or other procedures to calm the mind, and
then to shift one's awareness away from the physical senses.
The five physical senses are not the only hurdles confronting the
remote viewer. The thinking, judgmental, and evaluative processes of
the conscious mind can also inhibit success. The conscious mind can
contaminate accurately perceived information. The amount of
information the conscious mind has regarding the target during the
remote-viewing session has to be minimized.
Information coming from the subspace mind is typically called
"intuition." This is a feeling about something, which one otherwise
would have no direct knowledge of on the physical level of
existence. For example, many mothers say they know when one of their
children is in trouble. They feel it in their bones, so to speak,
even when they have not been told anything specific regarding their
child's situation. SRV systematizes the reading of intuition.
Using SRV, the information from the subspace mind is recorded before
the conscious mind has a chance to interfere with it using normal
intellectual processes such as rationalization or imagination. With
nearly all physical phenomena, a time delay exists between
sequential and causally connected events.
For example, when one turns on a computer, it takes awhile for the
machine to boot up. When the institute teaches remote viewing to
novices, we exploit the fact that there is approximately a
three-second delay between the instant the subspace mind obtains
information and the moment when the conscious mind can react to this
information.
The subspace mind, on the other hand, apparently has
instantaneous awareness of any desired piece of information. In
general, the novice viewer using SRV protocols moves steadily
through a list of, say, a few hundred things at basically a
three-second clip for each one. The tasks carried out in the
protocols are carefully designed to produce an accurate picture of
much of the target by the end of the session.
It is crucial to emphasize at this point that there must be no
deviation from the grammar of the protocols. This is particularly
true for novices. If there is a deviation, one only has to be
re-minded that it is the conscious mind that designs this deviation.
When this happens, the subspace mind loses control of the session,
and the data from that point on in the session are often worthless.
TARGET COORDINATES
Scientific Remote Viewing always focuses on a target. A target can
be almost anything about which one desires information. Typically,
targets are places, events, or people. But advanced viewers also
work with more challenging targets.
An SRV session begins by executing a set of procedures using target
coordinates. These are essentially two randomly generated
four-digit numbers that are assigned to the target.
The remote
viewer does not know what target the numbers represent, yet
extensive experience has demonstrated that the subspace mind
instantly knows the target even if it is only given its coordinate
numbers. The remote viewer is not told the target's identity until
after the session is completed.
For all of the remote-viewing sessions presented in this book, the
only thing I was given prior to the beginning of the sessions was a
fax or an e-mail from my "tasker" telling me the target's
coordinates. The tasker is someone who tasks or assigns a target.
For example, if the target was the Taj Mahal, I would not be told
to remote-view the Taj Mahal, since this would activate all of the
information held by my conscious mind regarding this structure,
meaning that I would have a difficult time differentiating the
remote-viewing data from memories or imagination. Instead, the
tasker would tell me that the numbers were, say 1234/5678.
My
conscious mind would not know what target is associated with these
numbers, but my subspace mind would know the target immediately A
productive session would then include good sketches of the
structure, or at least aspects of the structure, together with
written descriptive data of the building and its surroundings,
including people who may be in or near the building.
THE SRV PROTOCOLS
Scientific Remote Viewing has five distinct phases, which follow
one after the other during an SRV session. In each phase the viewer
is brought into either a closer or an altered association with the
target. SRV is performed by writing, on pieces of plain white paper
with a pen, sketches and symbols that represent aspects of the
target.
The viewer then probes these marks with
the pen to sense any intuitive ideas. Since the subspace mind perceives
all aspects at once, probing a mark is a way of focusing attention on the desired
aspect.
The five phases of the SRV process are as follows:
-
Phase 1. This establishes initial contact with the target. It also
sets up a pattern of data acquisition and exploration that is
continued in later phases. This is the only phase that directly uses
the target coordinates. Once initial contact is established, the
coordinates are no longer needed. Phase 1 essentially involves the
drawing and decoding of what is called an "ideogram" in order to
determine primitive descriptive characteristics of the target.
-
Phase 2. This phase increases viewer contact with the site.
Information obtained in this phase employs all of the five senses:
hearing, touch, sight, taste, and smell. This phase also obtains
initial magnitudes that are related to the target's dimensions.
-
Phase 3. This phase is a sketch of the target.
-
Phase 4. Target contact in this phase is more detailed. The
subspace mind is allowed significant control in solving the
remote-viewing problem by permitting it to direct the flow of
information to the conscious mind.
-
Phase 5. In this phase the remote viewer can conduct some guided
explorations of the target that would be potentially too leading to
be allowed in Phase 4. Phase 5 includes specialized procedures that
can dramatically add to the productivity of a session. For example,
one Phase 5 procedure is a locational sketch in which the viewer
locates a target in relation to some geographically defined area,
such as the United States.
CATEGORIES OF REMOTE-VIEWING DATA
Remote-viewing data can be obtained under a variety of conditions,
and the nature of these conditions produces different types of data.
There are six different types of remote-viewing data, and there are
three distinguishing characteristics of the various types of data.
The first distinguishing characteristic is the amount of information
the viewer has about the target prior to the beginning of the
remote-viewing session. The second is whether or not the viewer is
working with a person called a "monitor," explained below. The third
is determined by how the target is chosen.
-
Type 1 Data
When a remote viewer
conducts a session alone, the conditions of
data collection are referred to as "solo." When the session is solo
and the remote viewer picks the target (and thus has prior knowledge
of the target), the data are called Type 1 data.
Knowing the target in advance is called "front loading." Front
loading is rarely necessary and should be avoided in general, but
sometimes a viewer simply needs to know something about a known
target and has no alternative. Such sessions are very difficult to
conduct from a practical point of view. The viewer's conscious mind
can more easily contaminate these data, since the viewer may have
preconceived notions of the target. Rarely do
even advanced viewers attempt such sessions. Any findings are
considered suspect, and attempts are made to corroborate the data
with other data obtained under blind conditions (see Type 2 data).
-
Type 2 Data
When the
target is selected at random from a predetermined list of
targets, the data are called "Type 2" data. For this, a computer
(or a human intermediary) normally supplies the viewer with only the
coordinates for the target. Even if the viewer knows the list of
targets, since sometimes the viewer has been involved in designing
the list, only the computer knows which coordinate numbers are
associated with each target. It is said that the viewer is
conducting the session blind, which means without prior knowledge of
the target.
-
Type 3 Data
Another type of solo, blind session is used to collect Type 3 data.
In this case the target is determined by someone (a tasker). During
training, viewers may (rarely) receive some limited information
regarding the target—perhaps whether the target is a place or an
event. Advanced viewers are normally not told any-thing other than
the target coordinates.
Solo sessions can yield valuable information about a target, but
trainees often find that more in-depth information can be obtained
when someone else is doing the navigation. This other person is
called a "monitor," and monitored sessions can be spectacularly
interesting events for the new remote viewer.
-
Type 4 Data
There are three types of monitored SRV sessions. When the monitor
knows the target but communicates only the target's coordinates to
the viewer, this generates Type 4 data. These types of monitored
sessions are often used in training. Type 4 data can also be very
useful from a research perspective, since the monitor has the
maximum amount of information with which to direct the viewer. In
these sessions, the monitor tells the viewer what to
do, where to look, and where to go. This allows the viewer to
al-most totally disengage his or her analytic mental resources while
the monitor does all of the analysis.
One of the troubles with Type 4 data for advanced
practitioners is
that their telepathic capabilities become so sensitive that they can
be led during the sessions by the thoughts of the monitors. Even
slight grunts, changes in breathing, or any other signal, however
slight, can be interpreted as a subtle form of leading by the
monitor, which in turn could contaminate the data. To eliminate
these problems, advanced monitored sessions are normally conducted
under double-blind conditions, yielding Type 5 data.
-
Type 5 Data
For this level both the viewer and the monitor are blind, and the
target either comes from an outside agency or it is pulled by a
computer program from a list of targets. Sessions conducted under
these conditions by proficient viewers tend to be highly reliable.
The disadvantages are that such sessions do not allow the monitor to
sort out the most useful information during the session. To address
this limitation, scripts are often given to the monitor in advance
of the session. These scripts contain no target-identifying
information, but they do give clear instructions as to which
procedures and movement exercises need to be executed (and in what
order).
-
Type 6 Data
These data come from sessions in which both the monitor and the
viewer are front loaded with target information. This type of
session was occasionally used when there were very few
professionally trained viewers and monitors, information needed to
be obtained quickly and there was no one else available to task with
the session. Type 6 data are rarely if ever collected these days.
Descriptions of remote-viewing sessions in this book use Type 2 and
Type 3 data. The sessions using verifiable targets in Part II all
employ Type 3 data. When I conducted these sessions, I had
absolutely no prior knowledge of the targets in any way. For
the substantive sessions presented in Section 2, a mixture of Type 2
and Type 3 data are used.
I was involved in creating a list of approximately
20 highly varied targets for the Type 2 sessions. I gave the list of
targets to an intermediary who mixed them up, assigned random
coordinate numbers to each one, and then gave me the coordinate
numbers. I viewed all Type 2 targets in a batch before being told
the cue/coordinate associations.
The Type 3 data used in Section 2
involve targets that were designed by someone other than myself and
that were given to me blind.
THE REMOTE-VIEWING EXPERIENCE
When at peace inwardly, and generally stress free, beginners
perceive a target with a clarity characteristic of, say, a light on
a misty night. While there may be difficulty discerning the precise
meaning and distance of a light under such conditions, there is
nonetheless no doubt that a light is perceived. With experience and
skill, a remote viewer can perceive all sorts of details relating to
a target, just as an experienced yachtsman, upon seeing the light,
can soon discern the outline of the nearby coast, and the identity
of the lighthouse from which the shrouded beacon shines.
Learning how to remote view from a book is not optimal. The primary
reason for including these methods is not to teach Scientific
Remote Viewing, but to explain it to people who want to understand
and interpret remote-viewing data. Students of remote viewing must
understand that the effectiveness of any procedures depends not only
on the procedures themselves, but also on how well they are
executed.
This, in turn, depends on the quality of
instruction and feedback. In a classroom, regular instructions are directed at a
student's work while the initial learning process is under way (and
before counterproductive habits are formed). These instructions help
obtain the highest level of performance. Nonetheless, many students
can achieve a minimal level of effectiveness by systematically
studying the procedures presented here without the assistance of
classroom instruction.
The term "remote viewing" is actually not entirely appropriate. The
experience is not limited to visual pictures. All of the
senses—hearing, touch, sight, taste, and smell—are active during the remote-viewing process. More accurate is the term "remote
perception." Nonetheless, since "remote viewing" has been widely
adopted in the scientific as well as the popular literature, it
makes sense simply to continue using the current term.
When one looks at an object, the light reflected off that object
enters the eye, and an electrochemical signal is generated that is
transmitted along the optic nerve to the brain. Scientific studies
have demonstrated that this signal is "displayed" on a layer of
cells in the brain, the way an image is projected from a movie
projector onto a movie screen. The brain then interprets this image
to determine what is being seen. When someone remembers an object,
the remembered image of the object is also projected onto that same
layer of cells in the brain.*
* If one remembers an object and visualizes it while the eyes are
open and looking at something else, then the same layer of cells in
the brain contains two separate projected images. The image
originating from the open eyes is the brightest, whereas the
remembered image is relatively dim and somewhat translucent, since
one can see through the translucent image to perceive the ocular
originating image.
When remote viewing, one also perceives an image, but it is
different from the remembered image or the ocular image. The
remote-viewing image is dimmer, foggier, and fuzzier. In-deed, one
tends to "feel" the image as much as one visualizes it. The human
subspace mind does not transmit bright, high-resolution images to
the brain, and this fact is useful in the training process for SRV.
If a student states that he or she perceives a clear image of a
target, this image almost certainly originates from the viewer's
imagination rather than from subspace.
This does not mean that the relatively low-resolution remote-viewing
experience is inferior to a visual experience based on eyesight.
Remember that all of the five senses—plus the sense of the subspace
realm—operate during the remote-viewing process. Thus, it is
actually possible to obtain a much higher-quality collection of
diverse and penetrating data. The remote-viewing experience is
simply different from, not superior or inferior to, physical
experience of observation.
For those readers who would like to read an
accessible but more in-depth treatment of the physiology of visual
and remembered images, I strongly recommend an article in the New
York Times by Sandra Blakeslee titled "Seeing and Imagining: Clues
to the Workings of the Mind's Eye," New York Times, 31 August 1993,
pp. B5N-B6N.
A remote viewer's contact with a target can be so intimate that a
new term, "bilocation," is used to describe the experience.
Approximately halfway through a session, the viewer often be-gins to
feel he or she is in two places at once. The rate at which data come
through at this point is typically very fast, and the viewer has to
record as much as possible in a relatively short period of time.
Experience has shown that each viewer is attracted to certain
aspects of any particular target, and not all are attracted to the
same aspects. One viewer may perceive the psychological condition
of people at the target location, whereas another viewer may focus
in on their physical health. Yet another viewer may concentrate on
the physical attributes of the local environment of the target. For
example, I once assigned a target of a bombing to a group of
students. One of the students was a doctor and another a
photographer.
After the session was completed, I reviewed each
student's work. The entire class perceived the bombing incident.
But the doctor described the physical characteristics of the bombing
victims closely, including all of their medical problems resulting
from the bombing. On the other hand, the photographer's session
read more like a detailed analysis of the physical characteristics
of the event, including an accurate description of the geographical
terrain where the bombing took place.
Thus, remote viewers go into a session with what they al-ready
have—their own personalities. Advanced remote viewers balance these
attractions because their training is designed to ex-tract a
comprehensive collection of data. But even under the best of
circumstances, some level of individual focusing is inevitable for
each viewer. For this reason, we use a number of advanced remote
viewers for any given project. Each viewer will contribute something
unique to the overall results, and a good analyst can put the pieces
of the puzzle together to obtain the fullest analysis of the target.
So, you may ask, who should remote view?
In this field there is a distinction between natural and trained
remote viewers. Natural remote viewers are generally referred to as
"psychics," or when the context is clear, simply "naturals."
Naturals typically use no formal means of data acquisition. They
simply "feel" the target, and their accuracy depends on how well
they can do this.
Because naturals may not understand the
mechanism by which their talents are achieved, their dependency on
the "feel" of the data can cause problems of accuracy A person's
conscious mind can disguise information to make it feel right, when
in fact it is not correct at all. Furthermore, since it is difficult
to accurately evaluate the "flavor" of psychic data while it is
being collected, most naturals have very uneven success histories.
By the end of 1997, The Farsight Institute had trained a large
number of people in the basics of Scientific Remote Viewing. With
this teaching experience as background, we have identified a clear
pattern. Any person of average or better intelligence apparently can
be trained to remote view with considerable accuracy. Certain life
experiences and educational backgrounds sometimes assist in the
process.
In week-long introductory classes taught at
The Farsight
Institute, all or nearly all students have successful remote-viewing
experiences, and the instructors generally expect that most
sessions conducted after the third day contain some obviously
target-related material.
Part of the training process is helping participants identify and
interpret subspace-accessed data with increasing precision. All
aspects of all targets have a particular "feel." The novice viewers
are just beginning to learn what these aspects feel like on an
intuitive level.
In addition, Farsight Institute trainees who practice meditation
already have a good intuitive sense of subspace. Their initial
training moves quickly from learning the mechanics of SRV to the
advanced discrimination between complex target characteristics.
Meditators often discern new things and have more penetrating and
profound remote-viewing experiences more quickly than those who do
not meditate. Of course, there are exceptions: many remote-viewing
trainees are very good from the start even if they have never
meditated.
With this general discussion of Scientific Remote Viewing complete,
we are now ready to explain the mechanics of the process and how it
works. We begin this in the next chapter by explaining how we
identify a target using what is called a "target
Back to Contents
Chapter 3
TARGET CUES
Writing an effective target cue is one of the most important criteria
in remote viewing. The target cue identifies the target. It is the
actual event, person, object, or whatever, that is the focus for a
remote-viewing session. Normally the remote viewer is not told the
target cue until after the session is completed. With Type 5 data
(double-blind), the monitor also is not told the target cue until
after the session is completed.
The initial target cue is given through the target coordinates.
Typically the person who tasks the session has a piece of paper on
which the target coordinates and the target cue are both writ-ten.
In Type 5 data situations, the tasker gives the monitor the target
coordinates (normally over phone or fax), and nothing more.
Experience has clearly demonstrated that the viewer 's subspace mind
has instantaneous awareness of the meaning of the target
coordinates, and a typical session begins immediately by obtaining
information directly related to the target cue.
Humans perceive and process remote-viewing data differently For
example, if someone was told to go into a room and to see what was
there, they would need little additional instruction. The request to
go into the room and observe is vague, yet most people would not
feel uncomfortable with the request, knowing that they would
probably be able to sort things out once
they got into the room. When they start looking around, they could
make an inventory of the room's contents. Their conscious minds
would be fully engaged as they entered the room, and most people
would perform satisfactorily in this regard even if they had no
prior expectations regarding the contents of the room.
With remote viewing, the viewer has minimal help from the conscious
mind. The viewer cannot seen everything, evaluate the importance of
all that is perceived, make logical choices as to which are the
important things to observe, and rank them in order. The
remote-viewing experience is more passive; the viewer perceives what
is there, but the viewer has only limited evaluative capabilities.
Thus, for remote viewing to be most successful, it is necessary to
compensate for the relative lack of input from the conscious mind.
To do this, one makes the target cue very specific with regard to
what is desired from the subspace mind of the viewer.
At The Farsight Institute, we avoid excessively vague cues. For
example, if one tasks a target cue of a person (say just the
person's name), then a viewer would be completely accurate if the
observed data were anything that related to this person at any time
in his or her life. Even a fantasy that the person had during a
lunch break would qualify as accurate data. In such a situation,
the choice of what to perceive is being determined by the personal
preferences of the viewer's subspace mind. To avoid this problem of
subjectivity the instructions in the cue have to eliminate as much
ambiguity as possible.
In this chapter I will present one of the more modern forms of cuing
that is used at The Farsight Institute. Other cuing forms tend to be
more basic versions of that presented here, and readers will see
some of these other forms used in later chapters. None are better or
worse; they just do different things.
To task a target, one needs a "target definition." A complete target
definition has a variety of parts, but they are basically bro-ken
down into (1) viewing parameters, (2) the essential cue, and (3) a
list of qualifiers.
VIEWING PARAMETERS
Viewing parameters may contain a variety of components. They
typically begin with a declaration of the target coordinates.
Following this is the essential cue, as it is described below. The
target coordinates and the essential cue are placed at the top of
the cue so that analysts who sort through large stacks of targets
can identify a target by glancing at the top of the page.
Following the essential cue are two primary viewing parameters. The
first is the target range. This gives general instructions as to the
type of information that is permissible in the session. For example,
the range typically limits the target data to only tangibles and
intangibles that exist in the target. At first this may seem
obvious. However, all targets bleed into other areas, and it is easy
for the subspace mind to follow these smears in the data boundaries.
For example, the target may be a specific person on a beach on the
equator at a given point in time.
But that person may be thinking
about an Eskimo hunting a polar bear in the Arctic. If a viewer
pursues this perception, the viewer may describe polar bears on the
beach.
Then comes the second viewing parameter. This specifies the time
frame of the target. Many experiments have verified that there is a
complete continuum of existence with an infinite number of time
lines, both past, present, and future. The subspace mind is equally
capable of perceiving all of these. Thus, it is necessary to
request the subspace mind to locate targets as they may exist in
time frames and realities that are closely connected to our present.
Following the second viewing parameter is the target cue, which
includes the essential cue and the qualifiers.
THE ESSENTIAL CUE
The essential cue is normally a simple statement or sentence that
describes the basic core of the target. The essential cue is both
simple and direct. Sometimes a segmented structure is used in
writing the essential cue. The cue has multiple parts, with each
being separated by a slash (/). The first part of the essential cue
is
called the "primary cue." The primary cue is the major identifier of
the target. Everything that follows is a refinement of this primary
identifier. Thus, if the target is a known place or person, the
first part must be the name of the place or person.
The primary cue
is then followed by a slash and one or more secondary cues (each
separated by a slash) if greater refinement of the target is
required. The cue "event" is sometimes used as the final
secondary
cue to focus a remote viewer on activity at the target. Specific
temporal identifiers follow the primary and secondary cues and are
placed in parentheses. As a general rule, each target must have one
primary cue, and nearly all targets have at least one secondary cue
(as needed) as well as a temporal identifier.
The format of the
essential target cue is as follows:
Primary Cue /First Secondary Cue / Second Secondary Cue (Temporal
Identifier)
The following are some examples of essential target cues that follow
the segmented format.
Example 1
Napoleon Bonaparte / Battle of Waterloo / event (1815)
Example 2
John F. Kennedy assassination / event (22 November 1963)
Example 3
Nagasaki / nuclear destruction / event (9 August 1945)
Effective essential cues must begin with a known, not a
conclusion.
Errors in cue construction usually result from placing an analytical
conclusion in the cue itself. The purpose of a remote viewing
session is to gather data for known events so that conclusions can
be made during the subsequent analysis of the data.
For example, a
poorly written essential cue that contains a conclusion would be:
"John F. Kennedy assassination / conspiracy" In this cue, one is
assuming that there is a conspiracy in the assassination. With
remote viewing, one must construct a case for a conclusion based on
observable data. If there was a conspiracy in the J.F.K.
assassination, this must be established from the data of events and
people, not by cuing on the idea of conspiracy.
Since remote viewing always obtains descriptive information about
people, things, and events, the conscious mind must later make
conclusions based on information supplied by remote-viewing data.
For example, a remote viewer could be tasked the J.F.K.
assassination (that is, the event itself). The viewer could then be
given various movement exercises and cues to obtain as complete a
collection of data as possible. In the analysis that follows the
remote-viewing session, the analyst can then examine the data for
any evidence of a conspiracy
For instance, the data may show more
than one source of bullets in the event. But one cannot go into a
session assuming that there will be more than one source of bullets.
That would bias the data-collection process. Restating this
important principle, data are collected using neutral target cues,
and all analytical conclusions must be made after the
data-collection process is completed.
Another example of a poorly written essential cue is: "How to live
happily with friendly extraterrestrial neighbors." Many people
think that remote viewing can be used to resolve such targets
directly Yet it must begin with a known person, place, thing, or
event. A cue about extraterrestrial neighbors would assume the
existence of extraterrestrials. At best, one would have to begin
with a known, such as an actual sighting of an unidentified flying
object, perhaps one documented with a photograph.
The remote viewer
would then be able to target the object, try to move inside the
object, and observe extraterrestrials flying the craft. The viewer
would also be able to move into the minds of the extraterrestrials
to find out if they are friendly toward humans. With this
information, an analyst would have at least something to work with
regarding the possibility of friendly coexistence for humans and
extraterrestrials.
In general, remote viewing is descriptive. It does not label things,
analyze situations, make conclusions, nor does it employ logic or
reasoning during the session. For example, if the target is a
checkers game, the remote viewer would describe the board, perhaps
even drawing the checkerboard pattern in a sketch. The viewer may
even correctly place some pieces on the board, and identify the
colors of the pieces. But the viewer may not realize during the
session that the target is a checkers game. After the session is
completed, the analyst can examine the data and conclude that the
data seem to correspond with a checkers game.
The target cue has to focus on these descriptive capabilities of
remote viewing.
The Qualifiers
Following the essential cue is a list of qualifiers, usually marked
with bullets. The qualifiers are written in phrase or sentence
for-mat, and they are clear descriptions of specific things that the
viewer is supposed to observe and describe. The qualifiers must
address the primary goals of the cue, including instructions to
observe activity that may be taking place at the target location.
For example, if the cue is a military battle, the qualifiers should
explicitly state that the viewer is to observe the battle itself.
Other-wise a viewer may perceive what amounts to an inventory list
of things and people that are at the scene of the battle, but miss
the actual fighting, the sounds of the passing cannonballs, the
thunder of the bombs, the shouts of the soldiers, etc.
Readers are encouraged to closely examine the qualifiers for the example target
cues listed below to obtain a solid sense of what's required.
Versions of some of these targets have been used in the actual
training of many advanced viewers at The Farsight Institute.
One Complete Example
TARGET DEFINITION FOR TARGET 3292/9537
ESSENTIAL CUE (AND VIEWING PROTOCOLS): Mike Tyson-Evander Holyfield
Championship Boxing Match (28 June 1997). (ESRV)
VIEWING PARAMETER 1: TARGET RANGE
The viewer perceives only the intended target as it is specified by
this complete target definition. The viewer describes only
tangibles and intangibles that exist in this target.
VIEWING PARAMETER 2: TARGET LINKS
If the target resides outside of a past, present, or future
connection to the temporal and/or spatial reality of the current
tasking
time frame, then the viewer remote views the target as it exists in
its own reality.
If the target time is the moment of tasking, then the viewer
remote
views the target as it exists in the same temporal and spatial
reality of the tasker at the moment of tasking.
If the target time is prior to the moment of tasking, then the
viewer remote views the target as it exists in the temporal and
spatial reality of the time stream that directly evolves into the
temporal and spatial reality of the tasker at the moment of tasking.
If the target time is in the future of the moment of tasking, then
the viewer remote views the target as it exists in the most highly
probable temporal and spatial reality as it may evolve from the
temporal and spatial reality of the tasker at the moment of tasking,
given both the existing conditions of the tasker's reality at the
moment of tasking, as well as directions for extrapolation into the
future if such are specified in the target cue.
TARGET 3292/9537
Protocols used for this target: Enhanced SRV
The Mike Tyson-Evander Holyfield Championship Boxing Match (28 June
1997). In addition to the relevant aspects of the general target as
defined by the essential cue, the viewer perceives and describes the
following target aspects:
• Mike Tyson and Evander Holyfield
• the target
activity in the boxing ring
• the activity surrounding the boxing ring
• the
building within which the target ¡s located
• the thoughts of the people
watching the fight inside the building
where the match occurs
Examples of Essential Cues with qualifiers
TARGET 9148/5716
Madeleine Murray O'Hare / current location. In addition to the
relevant aspects of the general target as defined by the essential
cue, the viewer perceives and describes the following target
aspects:
• the current physical characteristics of Madeleine Murray O'Hare
• the current physical condition of Madeleine Murray O'Hare
• the surrounding environment and current location of Madeleine
Murray O'Hare's physical body
TARGET 3985/3159
The Apollo 11 landing on the Moon / event (20 July 1969). In
addition to the relevant aspects of the general target as
defined
by the essential cue, the viewer perceives and describes the
following target aspects:
• the actual landing event in which the lander contacts the lunar
surface
• the activity of Neil Armstrong as he emerges from the lunar lander
and walks on the lunar surface for the first time
• Neil Armstrong planting the U.S. flag on the lunar surface
TARGET 6459/3395
Ted Bundy's execution / event. In addition to the relevant aspects
of the general target as defined by the essential cue, the viewer
perceives and describes the following target aspects;
• Ted Bundy during the execution event
• Ted Bundy's surroundings during the moment of execution
• the people near Ted Bundy during the execution
• the emotions of Ted Bundy as well as the emotions of the people
near him who are watching the execution
• the method by which the execution is performed
Here is an esoteric target. Before giving an esoteric target with an
extensive list of qualifiers, the tasker must have some in-formation
strongly suggesting that such a target in fact exists. Such
information can come from more open-ended cues.
TARGET 3292/9537
The living physical subjects and their facilities that are currently
located on Mars (at the time of tasking). In addition to the
relevant aspects of the general target as defined by the essential
cue, the viewer perceives and describes the following target
aspects:
• the physical environment of the subjects' living conditions
• the age and gender variations among the subjects
• the emotional state of the subjects
• the dominant groups among the subjects, ¡including any governmental
organizations
• the primary thoughts of the collective consciousness of the
subjects
• the level of technology available to the subjects
Back to Contents
Chapter 4
PHASE I -
THE PRELIMINARIES
1. Consciousness-Settling Procedure
The single most important step needed to obtain a profound
remote-viewing experience is a deeply settled mind. For this reason
I recommend that remote viewers meditate regularly. While I
personally practice Transcendental Meditation (TM), other forms of
meditation may be useful as well.
Additionally, since a settled
mind is so essential to deep target penetration, the practice of
SRV begins with a procedure that helps to settle the mind in an
appropriate fashion. This practice is called the SRV
"Consciousness-Settling Procedure" (or CSP), and it is composed of a
few simple techniques commonly practiced in a number of meditation
traditions.
CSP must be done immediately prior to each SRV session by both the
viewer and the monitor. CSP takes approximately 15 minutes total. In
Type 4 and Type 5 settings, monitors and viewers need to
communicate 15 minutes before each session to coordinate the
precise timing of the beginning of the SRV session. Here are the
steps for CSP:
1. Sit comfortably in silence with the eyes closed for 30 seconds.
2. Perform a brief body massage. (Some meditation
traditions
recommend that the massage be executed slightly differently for men
and women, and I describe these recommendations here. I am not
clear as to why these gender-related differences exist, or if the
need for the differences is real.) The massage begins by gently
pressing the hands against the face, then upward on the top of the
head, back down the neck, and toward the heart. (All massage
elements move toward and finish at the heart.)
Then men continue by
gently using the left hand to press and massage first the right
hand, and then up the arm, and back down toward the heart. Again,
this is all done with the left hand. Women do the same, but they
begin by massaging the left hand and arm (back toward the heart)
with the right hand. Then both men and women switch arms and massage
the other hand and arm, again, back toward the heart. Then men
continue by massaging the right foot and leg, upward toward the
heart.
This is done with both hands pressing gently. Then massage
the left foot and leg, again, upward toward the heart. Women do the
same, but they begin with the left foot and leg, upward toward the
heart, before repeating the process for the right foot and leg. This
is best done with the eyes closed. Total time for the massage is
about a minute.
3. While sitting comfortably with the back straight, perform a
breathing technique that is called "pranayama." Begin with 10
seconds of fast pranayama. This is done using very short, gentle
breaths, closing one nostril at a time after each outward and inward
breath. Close the nostrils (one at a time) with the thumb and the
middle fingers (alternately) of one hand. Men use their right hand
to do this while women use their left.
The mechanics of the procedure are similar to slow pranayama (see below), except that
the breaths are very short and rapid (although still gentle). This
is best done with the eyes closed. The procedure should be
effortless and easy, and if someone is experiencing any problems
like dizziness or hyperventilation, it is being performed
incorrectly and its practice should be
discontinued until getting personal instruction in this technique.
4. While sitting comfortably with the back straight, perform 9 to 10
minutes of slow pranayama. This is done similarly as with the fast
pranayama, but using normal breaths (not short or long ones),
closing one nostril at a time after each outward and inward
breath. Be sure to complete both the outward and inward
breath before switching nostrils. On the exhaling breath,
let the breath flow out naturally not forcing it. The
inhaling breath should take about half the time as the
exhaling breath.
Hold the breath after inhaling
for a brief moment (a second or two) while alternately
closing the other nostril with the other finger, and prepare
to exhale. The entire procedure should be effortless and
gentle. If you feel you need more air, simply take deeper
breaths, but do not hyperventilate. You should be breathing normally just alternating nostrils after
exhaling and inhaling. This is best done with the eyes closed.
5. Sit quietly and comfortably for 5 minutes with the eyes closed.
6. Open your eyes and immediately begin the SRV session.
2. Physical Considerations to Beginning the SRV Session
A remote-viewing session begins with a viewer sitting at a clean
desk. Ideally, the only items that should be on the desk are a pen
and a thin stack of white paper. We use a ballpoint pen with liquid
black ink. A good quality pen that does not produce much friction
when writing is best. Traditional ballpoint pens that use gummy ink
require too much downward pressure when writing.
The ideal training room is neutral in color. Light gray, powder
blue, or light brown are suitable colors. It is probably not a good
idea to use, say a child's playroom that has lots of primary colors
on the walls. The idea is to minimize the strong stimuli that come
in through the senses, such as bright visual colors.
Before remote viewing, a person should be well rested. This cannot
be emphasized enough. Tiredness dulls the conscious mind, and a
tired conscious mind has difficulty perceiving information
originating from the subspace mind. A good night's sleep
is ideal for a morning remote-viewing session, and a midday
15-30-minute rest often refreshes one sufficiently for an after-noon
session.
One should be comfortably fed before remote viewing. This means that
one should not be hungry and one should also not be overfed. Hunger
and feeling stuffed produce physical stimuli that are difficult for
the conscious mind to ignore. Remember that the subspace mind yields
a relatively weak informational signal to the conscious mind. Try to
minimize any physiological stimuli that could swamp the subspace
signal.
Remote view in a quiet environment. If possible,
close the windows
and doors of the remote-viewing room. Also turn off the ringer of
the phone for the time that it takes to complete the session. Turn
off any radios or televisions that may be audible nearby
Avoid wearing any perfume, cologne, aftershave, or other strong
scents. This is particularly important when training in a group
environment. If a viewer is a smoker, it would be best if this
viewer wore freshly washed clothes during the session that do not
smell of smoke.
People who use recreational drugs, or any other drugs with
psychoactive qualities, should not remote view at all. These drugs
tend to release any controls that the conscious mind has over the
imagination, which is exactly opposite that which is required for
successful remote viewing. With respect to drugs of any type, one
should try to be as drug free as possible. Individuals who use
doctor-prescribed antidepressants should probably not spend much
effort trying to remote view.
Such antidepressants suppress the
nervous system to such a degree that accuracy in remote viewing is
highly compromised. Yet individuals using any drugs prescribed by
their doctors should not discontinue their use unless directed to do
so by their doctor. Learning how to remote view is not as important
as maintaining one's health and mental balance.
Before beginning the session, you should sit comfortably on a chair
at your desk with both feet on the floor. The legs should not be
crossed. You should sit up straight, not off to one side, or
sit-ting on one foot in a lotus position. The hands should be
relaxed, with the pen held over a single clean sheet of paper. The
paper is
positioned in portrait mode (vertically). The stack of paper should
be on the viewer's right side of the desk.
THE SRV AFFIRMATION
The SRV Affirmation is normally read aloud with a soft voice, even
in solo sessions. The affirmation produces a subtle shift in the
sensitivities of the mind that helps to connect the aware-ness of
the conscious mind to the perceptive capabilities of the subspace
mind.
The SRV Affirmation is designed to closely approximate the
way sequential, connected thoughts are felt telepathically piece by
piece, one "thought-ball" at a time. Viewers should read the
affirmation slowly pausing briefly after each comma or period.
Here
is the SRV affirmation:
SRV Affirmation
l am a spiritual being. Because l am a spiritual being, I am able to perceive
beyond all boundaries of time and space. My consciousness is ever
present with all that is, with all that ever was, and with all that
ever will be. It is in my nature, as a human, to be able to
perceive, and thus to know, all that there is to know. Everywhere,
at all times, I seek to learn, and thus to evolve. To further my own
personal growth, and to assist others in their growth, I direct my
attention to a chosen point of existence. I observe what is there. I
study it carefully. I record what I find.
THE HEADER
Next, write the SRV identifying header on the top of the first piece
of paper. The viewers declare the condition of their physical state
(PS), their emotional state (ES), or any advanced perceptual (AP)
centered at the top of the first page. Declaring PS and ES let the
conscious mind account for your physical and emotional states,
thereby releasing any psychological pressure that could be present.
These declarations can be positive, neutral, or negative. Positive
declarations include, "I really have a happy glow this morning," or
anything else that is upbeat. Negative declarations include having
a sore foot, or being upset with the
quality of lunch. Unusually strong PS or ES declarations, such as
just having had a fight with a spouse, may suggest that the session
might be postponed until later. Similarly if one is in significant
pain due to, say severe arthritis, it might be better to delay the
session until the pain abates.
In some ways it is useful to compare the conscious mind to the
mentality of a small child. When the conscious mind is experiencing
something, it likes to be heard. Declaring the PS and the ES
satisfies this need. This helps the conscious mind relax, circumventing its natural desire to
force the issue of having its
needs recognized later in the session, potentially corrupting the
integrity of the data.
Often a viewer begins a session thinking that he or she has an idea
as to what the target is. Such ideas are advanced perceptual, and
any thoughts along these lines need to be declared at the outset, or
they will build in pressure in the conscious mind during the
session, and are likely to emerge in some form during the actual
data flow. Declaring these APs in advance again relaxes the
conscious mind by satisfying its desire to be heard, thereby
minimizing the risk of contaminating the data.
To the right of the PS, ES, and AP is the identifier of the remote
viewer. At The Farsight Institute we use a code called a viewer
identification number (VIN), but a name would do just as well. Below
the name or viewer identifier is the date written in the U.S.
military or European format (day/month/year). Below this is the
beginning time of the remote-viewing session.
To the left of the page is the data type, and below that is written
the monitor's name or identification number (MIN—if the session has
a monitor).
To summarize, the format of the initial header is as
follows:

Readers are encouraged not to perceive this initial header as a
frivolous formality Everything is carefully structured in SRV.
Following these details from the outset of the session focuses the
attention of the conscious mind on the structure of the page.
Further, trainee viewers should follow all of the seemingly petty
structural details of these protocols, including for-matting issues
involving indentations, dashes, and colons.
Once a remote-viewing session is
proceeding at a fast speed, the conscious mind can do little else but keep track of these
structural details. This frees the informational conduit of the
subspace mind from the controlling influence of the conscious mind.
Figuratively, this ties the hands of the conscious mind with
activity, allowing the subspace mind to slip the data past the
conscious mind with minimal interference.
THE IDEOGRAM
After saying the SRV affirmation, the viewer receives the tar-get
coordinates from the monitor. The monitor makes sure to speak
deliberately and clearly so that all the numbers can be heard. The
target coordinates are two four-digit random numbers, and the
monitor places a slight pause between the two groups of numbers. On
the left side of the page, the viewer writes the first four-digit
number, then the second four-digit number directly under the first.
After writing the target coordinates, the viewer immediately places
the point of the pen on the paper to the right of the coordinates.
At this point an ideogram is drawn. An ideogram is a spontaneous
drawing that takes only a moment to complete. The pen does not leave
the surface of the paper until the ideogram is completed. Ideograms
normally are simple, but complex ideograms can occur. In general,
each ideogram should represent one (and only one) aspect or
"gestalt" related to the target. For example, if the target is near
a body of water, an ideogram could represent water. If there is an
artificial structure at the target site, another ideogram could
represent this structure, and so on.
Only one ideogram is written for each recitation of the target
coordinates. In Phase 1, the monitor usually recites the target
coordinate numbers three to five times, enabling the viewer to draw
and decode a few ideograms, thereby obtaining information relating
to different target gestalts. Each time the viewer writes down the
target coordinates, it is said that he or she is "taking" or
"receiving" these coordinates.
After drawing the first ideogram, the viewer then writes the
capital letter "A" followed by a colon to the right of the
ideogram. The viewer then describes the movement of the pen while
writing the ideogram, writing this all down after the "A:". The
description must describe the process of the pen's movement without
the use of labels. The following words are generally acceptable in
this regard: vertical upward, vertical downward, diagonal upward,
diagonal downward, sloping (upward or downward), curving (upward or
downward), moving (upward, downward, or across), slanting (upward or
downward), curving over, curving under, horizontal flat across,
horizontal flat along, angle.
Words ending in "ing" or "ward" are
generally preferred. Labels such as "a circle/' "a loop/' or "a
square" are to be avoided. Labeling adds conceptual meaning to data
in remote viewing, and that is conscious-mind analysis. All of
remote viewing is built upon perceptions that begin at the lowest
level of conceptual abstraction and gradually move to higher levels
of abstraction. In the beginning of Phase 1, the lowest level of
conceptual analysis is required.
PROBING THE IDEOGRAM
This is a delicate matter. The viewer places the point of the pen on
the ideogram itself and gently (but firmly) pushes the pen down ward
(into the table). The novice viewer can probe one or more times but
should avoid more than four attempts. Each probe lasts between one
and two seconds (no longer than three seconds). While the pen is in
contact with the line, the viewer normally perceives some feeling
about the target.
Too brief a contact does not allow the nervous
system to register the impression sufficiently to allow for accurate
decoding. Too long a contact al-lows the conscious mind to intervene
in the process and distort or fabricate the data. After the probe,
the pen is removed from the ideogram, and the viewer searches for a
word to describe the sensation that was perceived during the probe.
The first time that the viewer probes the ideogram, the at-tempt is
made to discern what is called a "primitive descriptor," of which
there are six possible choices, with one exception. These are; hard,
soft, semi-hard, semi-soft, wet, or mushy. While probing the
ideogram, the viewer will actually sense the pen moving into the
paper and table if the target is soft, wet, or mushy
Although this seems logically impossible
due to the firmness of the writing surface, it nonetheless is
consistently perceived by viewers. When gently pushing the pen into
the paper, it will also feel wet if the target has water. The viewer
must choose only one of the six possible descriptive options given
above. No substitutions should be made, since this would invite the
conscious mind to enter the process more fully The choice of
primitive descriptors is then
written under the written description of the movement of the pen.
The one exception to picking one of the six primitive descriptors
is if the viewer perceives movement or energetics in the ideogram.
If this occurs, the viewer may or may not also perceive one of the
six primitive descriptors. If the viewer does, then the chosen
descriptor is declared and the viewer proceeds with the next step.
However, if you perceive only movement or
energetics, abandon the
attempt to perceive a primitive descriptor and move directly to
declaring an advanced descriptor.
After obtaining a primitive descriptor, the viewer probes the
ideogram again to obtain what is called an "advanced descriptor."
There are five choices, and the viewer must use only one of these
choices. These are: natural, man-made, artificial, movement,
energetics. After probing the ideogram, the viewer writes the
advanced descriptor under the primitive descriptor.
Readers should note that there is a difference between "man-made"
and "artificial." While everything that is man-made is
artificial,
not everything artificial is man-made. For example, a beaver dam is
artificial, but it is not man-made. Note also that energetics
refers to a feeling that the target is associated with some
significant quantity of energy. This energy can be in any form:
kinetic, radiant, explosive, etc. While movement can also indicate
an expenditure of energy, the movement of a snail or a slowly driven
car might not be perceived as energetics.
Underneath part A, the viewer writes "B" followed by a colon. The
viewer then declares what he or she perceives the ideogram to
represent. The most common declaration is "No-B." While you must
have one primitive descriptor and one advanced descriptor per
ideogram, you do not have to declare a substantive B. However, the
viewer must at least write "No-B."
For B, there is no fixed list of possible declarations. To assist
students, however, we offer a list during the first few days. The
list is: No-B, structure, water, dry land, wet land, motion,
subject, mountain, city, sand, ice, swamp.
Note that these declarations are at a higher level of abstraction
than when describing the movement of the pen while drawing the
ideogram. The entire process in Phase 1 moves from lower to higher
levels of abstraction as follows: describing the movement of the
pen, primitive descriptors, advanced descriptors, and an
interpretive declaration of the meaning of the gestalt. Yet the
viewer must remember that the declaration that is made in part B is
still very low-level.
For example, a viewer could not declare that
the gestalt represents an automobile, a computer, a skyscraper, or a
spaceship, since these declarations would be far too high-level,
involving conscious-mind interpretations that greatly exceed the
quality and quantity of data that are available at this point in the
session. For example, if the target really is a skyscraper, then the
best that could be determined at this point is that the target is
associated with a structure.
Following the declaration of B, the viewer writes "O" followed by
the viewer's intuitive perceptions about what the ideogram feels
like. This is usually just a word or two that describes very
low-level perceptions relating to the ideogram. Examples of such
perceptions are colors or textures (such as rough, smooth, polished,
etc.). The viewer may also feel the perception of size, such as big
or small, short or tall, wide or narrow. A viewer may also write
"No-C" if the previously declared data capture all of the ideogram's
nuances.
To summarize, the Phase 1 procedures are:
(1) take or receive the
target coordinates,
(2) draw an ideogram,
(3) describe the movement
of the pen during the drawing of the ideogram using process terms
rather than labels,
(4) probe the ideogram for primitive
descriptors,
(5) probe the ideogram for advanced
descriptors,
(6)
make an initial declaration of a low-level description of the
target aspect that is captured by the ideogram, or simply state that
there is no declaration (Le., No-B), and
(7) list other intuitive
feelings regarding the ideogram, if there are any.
This entire sequence is typically done three to five times in Phase
1 (going through all seven steps each time). The idea is not to use
Phase 1 to identify all of the aspects of the target, but rather to
establish initial contact by describing a few of the primary target aspects only. The viewer then proceeds immediately to
Phase 2.
One final note about the ideograms: if an ideogram is not de-coded
correctly it is nearly always immediately repeated with the next
taking of the coordinates. Thus, a self-correction factor is built
into the Phase 1 procedures. If an ideogram returns subsequent to a
different ideogram emerging from a different taking of the
coordinates, this indicates that the initial ideogram was de-coded
correctly previously, and that most or all of the primary gestalts
have been properly expressed. After decoding a repeating ideogram,
the viewer moves on to Phase 2.
For example, let us say that the first ideogram is decoded as a
structure. The second ideogram looks different, and from this we
assume that the first ideogram was decoded correctly. We decode the
second ideogram saying that it is hard and natural, with a B: of
"land." On the third taking of the target coordinates, the
second
ideogram returns. This tells us that we most likely made a mistake
in decoding something in the previous (second) ideogram.
We probe
again, this time finding that the ideogram really feels more like it
is hard and man-made. We declare "No-B." We take the coordinates
again and the structure ideogram returns. Now we know that we have
exhausted all of the major gestalts. We then decode the final
ideogram and move on to Phase 2. After the end of the session, we
find out that the target was a shopping mall containing a structure
and a large parking lot (that is, man-made land).
IDEOGRAM DRILLS
Students need to develop skill in drawing ideograms. Practice and
some drills are required. Our students typically drill with a few
standard ideograms that have established meanings. They are
"established" because many viewers use these same ideograms to
represent the same things. Usually seven or eight pages of drills
are all that is required to set in place the initial ideogram
vocabulary In the drill, an instructor repeats words like
"structure," and the student quickly draws a structure ideogram.
Common ideograms that are useful for drill purposes are presented in
Figure 4.1 below.
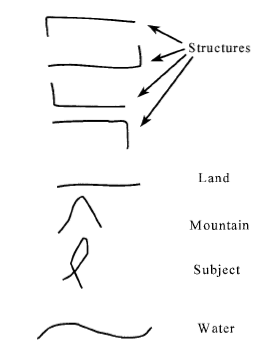
Other ideograms are developed individually for each student. Such
ideograms do not have a set pattern, and may vary widely from person
to person. Ideograms for such things are drilled not by telling the
student what the ideogram looks like, but by just repeating the
gestalt (such as the word "movement"), allowing the student to draw
whatever comes naturally. The ideograms typically settle down into a
set pattern for each gestalt after only a few repetitions.
"Person"
or "subject" ideograms are often very individualistic in this
regard. As a result of these drills, most students develop a minimum
of five or six distinct patterns in their ideogram vocabulary Should
a student ever develop an "ideogram rut," in which all ideograms
always look alike, then 10 minutes of drill using a variety of
ideograms usually fixes this problem.
DEDUCTIONS
What do you do if the conscious mind makes a high-level guess as to
the identity of the target or target fragment? This is called a
"deduction." A deduction has two components. First, it is a
conclusion (as in "to deduce") that the conscious mind makes
regarding the target. The conscious mind is basically watching the
data flow between the subspace mind and the physical body (the hand
holding the pen).
The conscious mind needs very little information
before it leaps into the process with a guess as to the meaning of
the data. This conclusion may indeed be correct, but the viewer
cannot know until the target identity is revealed at the end of the
session. Thus it is important to remove the conclusion from the data
recording process, which leads to the other half of the meaning for
"deduction." A deduction is also a subtraction from the data flow.
If this high-level conclusion is removed from the data collection,
it will not contaminate the remainder of the data flow.
Nearly all deductions describe some true aspect of the target, but a
remote viewer doesn't know during a session what that aspect is.
For example, if a target is the destruction of the Hindenberg
blimp, it follows that kite, balloon, fireworks, and TWA Flight 800
could all be deductions. The idea of a kite captures the notion that
the Hindenberg flew, the balloon reflects the structure of the
blimp, fireworks reflect the explosion that resulted in the
destruction of the Hindenberg, and TWA Flight 800 identifies the
idea that an airborne vehicle carrying passengers exploded causing
loss of life.
Do not worry about the inaccuracies inherent in deductions.
Remember, deductions are not remote-viewing data. They are guesses
made by the conscious mind, nothing more. However, deductions can be
very useful when analyzing the data after-ward. Deductions can
convey meaning about a target that is difficult to express. For
example, someone could be remote viewing a slave labor camp during
the time of the Pharaohs, and give Auschwitz as a deduction.
Such a
deduction has many parallels with the actual target. Jews were the
subjects of slavery, repression, misery, and death in both
settings. But more important, the analyst may be alerted to the
magnitude of the misery that was
experienced in Egyptian slave labor camps through the deduction of
Auschwitz. This could be useful in interpreting the remainder of
the session should the viewer describe extreme levels of suffering
among the actual target subjects.
Regardless of the potential accuracy of deductions, they must be
eliminated from the flow of the data. To accomplish this, the viewer
writes a capital letter "D" followed by a dash and the description
of the deduction on the right-hand side of the paper. Thus, the
deduction mentioned above would be written as "D-Auschwitz."
Following this, the viewer must put the pen down on the table for
one or more seconds. This action of putting the pen down breaks the
flow of the data from the subspace mind, thereby allowing the
impression that was made on the conscious mind to dissipate. After a
few moments the viewer picks up the pen and continues with the
session.
Back to Contents
Chapter 5
PHASE 2
Phase 1 initiates contact with the target. Phase 2 deepens that
contact by systematically activating all of the five senses:
hearing, touch, sight, taste, and smell. In Phase 2, viewers write
down various cues as well as their initial impressions of these
cues. In early training (the first three days), these steps are
per-formed slowly so that students can commit the mechanics of the
process to memory. Once this is done, the speed of these steps
dramatically increases.
Phase 2 begins by writing "P2" centered at the top of a new sheet of
paper. In general, all phases must begin with a new sheet of paper
regardless of how much space is left on the previous piece of paper.
The page number is entered on the upper right corner of the new
page.
The viewer begins by writing the word "sounds" followed by a colon
on the left side of the page. Immediately after writing this, the
viewer normally perceives some sense of sound, although this is
obviously not a physical perception. To assist the new viewer in
building a vocabulary for this phase, the instructor often recites
a list of sounds from which the viewer can choose one or more.
This
list includes the following: tapping, musical instruments, laughing,
hitting, flute, whispering, rustling, whistling, horn, clanging,
voices, drums, barking, humming, beating, trumpets, vibrating,
crying, whooshing, rushing,
whirring. The viewer will often perceive a variety of sounds, and
should record all of these perceptions as rapidly as possible.
The viewer then cues on textures that are associated with the
target. This is done by writing the word "textures" on the left side
of the page, followed by a colon. While writing the cue or
immediately afterward, the viewer will sense certain textures and
write them down after the colon. To help students during the first
few days of training, the following list of textures is read: rough,
smooth, shiny polished, matted, prickly sharp, foamy grainy slippery
wet.
The next sensation is temperature. The viewer writes the
abbreviation "temps" on the left side of the page, followed by a
colon. As before, one or more temperatures will be perceived
immediately, and the viewer must write these down following the
colon. The list of possible temperatures that is read to the beginning student is: hot, cold, warm, cool, frigid, sizzling.
The viewer then cues on visuals. These
have three components. To begin, the viewer writes "visuals" on the
left side of the page followed by a colon. Dropping down and
indenting, the viewer writes "colors" followed by a dash (not a
colon). The list of colors that is read to the viewer is: blue,
yellow, red, white, orange, green,
purple, pink, black, turquoise (and others). The viewer may write
down colors from this list, or may perceive other colors. In any
case, the list is no longer read after the first few days.
On the next line, also indenting as with colors, the viewer writes
"lum" for luminescence. As with colors, the cue is
followed by a
dash, not a colon. The list of possibilities is: bright, dull, dark,
glowing.
The final visual is contrasts. This cue is written under "lum," and
is followed by a dash. The list of possible contrasts is: high,
medium, low.
Dropping down again, but now returning to the left side of the page
(that is, no longer indented), the viewer cues on tastes. This is
done by writing the word "tastes" followed by a colon. The list of
possible tastes is: sour, sweet, bitter, pungent, salty.
The final cue for the five senses is smell. The viewer writes the
cue "smells" on the left side of the page followed by a colon. As
with all other cues, the viewer will immediately perceive some
smells, and these must be recorded without delay The list
of possible smells is: sweet, nectar, perfume, flowers, aromatic,
shit, burning, dust, soot, fishy, smoke (also cold and hot).
After recording the data from the five senses, the viewer is
normally drawn much closer to the target. Evidence of this is that
the viewer almost always perceives many magnitudes of the target.
Most magnitudes are essentially quantities. They tend to answer the
question of "How much?"
To probe for these target aspects in Phase 2, the viewer first
indents on the page and writes "Mags" followed by a colon. Dropping
down and indenting further, the viewer cues on the various types of
magnitudes shown in the following list. The viewer should not write
down the cues for the magnitudes, since these cues are long and this
could dangerously slow down the recording of the data.
Here is the list of cues and a collection of possible choices.
Advanced viewers typically develop a larger vocabulary of descriptive magnitudes.
-
[VERTICALS] high, tall, towering, deep, short, squat
-
[HORIZONTALS] flat, wide, long, open, thin
-
[DIAGONALS] oblique, diagonal,
slanting, sloping
-
[TOPOLOGY] curved, rounded, squarish, angular,
flat, pointed
-
[MASS, DENSITY, SPACE, VOLUME] heavy, light, hollow,
solid,
large, small, void, airy huge, bulky
-
[ENERGETICS] humming,
vibrating, pulsing, magnetic, electric, energy penetrating, vortex,
spinning, churning, fast, explosive, slow, zippy, pounding, quick,
rotating
The viewer must perceive magnitude data for at least three of the
six dimensions before proceeding further. If the viewer fails to
perceive data for at least three, the viewer is undoubtedly editing
out data.
In the beginning of training, a viewer sometimes claims not to
perceive anything. This is almost always a matter of editing out
data, which occurs when the conscious mind enters the remote-viewing
process and makes a decision that a piece of data cannot be correct.
This is usually perceived as doubt in the mind of the remote viewer.
To remedy this, an instructor encourages the student not to edit out
anything, and to write down the data immediately. This
raises an important point. It does not matter how the conscious mind
is occupied as long as the viewer stays within the structure of the
remote-viewing protocols. This means that the viewer need only keep
track of what is to be done next, and to mechanically perform that
duty correctly.
DECLARING THE VIEWER FEELING
At the end of recording dimensional magnitudes, the viewer begins to
perceive aspects of the target very strongly These aspects could be
anything: emotional, physical, or whatever. When this happens, the
viewer's conscious mind responds to the data, and this response must
be declared in order to limit its ability to contaminate the data
not yet collected. This response is called a "viewer feeling," and
it is declared by writing the letters "VF" followed by a dash, and
then the declaration of the feelings of the viewer. The viewer's
feeling is not the viewer's perception of the target. Rather, it is
the viewer 's gut response to the target.
The viewer must have a viewer feeling at the completion of the
initial pass through Phase 2, but it is not required or even
de-sired that the viewer feeling be dramatic. The viewer's gut
response can be simply, "OK," if that is how the viewer feels at
that point. A list of common examples of viewer feelings is: I feel
good, disgusting, I feel happy, interesting, awful, this place
stinks, this is gross, I feel light and lifting, I feel spiritual,
enlightening, wow!
The most important thing to remember
about the viewer feeling is that it is not data. It does not
describe the target. It describes the viewer's emotional response to
the target. By declaring the viewer feeling, we acknowledge it and remove it
from the data flow.
After declaring any viewer feeling, the viewer must put the pen down
momentarily, letting the feeling dissipate before picking up the pen
again and continuing with the session. In this regard, a viewer
feeling is treated similarly to a deduction.
Back to Contents
|